
REST Services are considered stateless. Therfore a Rest Service must not hold any client state. If so REST Services can be scaled easily by adding new server nodes without to worry about session replication. But this also means that a REST-Client must send all authentication information with every request. There are several techniques to handle that and each of them has it’s pros and cons. This blog wants to discuss some different approaches.
Why not just using stateful application services?
The simplest way to implement authentication in an application service is to make it stateful. This means that the application service is aware of requests that the client made before some request. Therefore an application service remembers that the client has been logged in and holds the application’s state, e.g. some data that the client sended before in order to complete a some kind of form.
Http session and scalability
A stateful application service is normally implemented by using a http session. Some kind of identifier with which the server side resources are associated. These server side resources are hold in the servers memory. In java one can get access to these resources via the HttpSession object that one can obtain from the HttpServletRequest, e.g.
public void doGet(HttpServletRequest request, HttpServletResponse response) {
HttpSession session = request.getSession();
String username = (String) request.getAttribute("username");
}
Since the application service holds resources associated with the client’s session identifier in it’s memory a client can not simply switch over to the same application service on another server node, becaue this server does not have the resources nor the session identifier in it’s memory. If the another server node should have the same resource in memory there must be some kind of session replication. But the session replication costs increase dramatically if more and more server nodes are added and represent a natural boundary for application scaling.
Http session and memory leaks
With a server side application session comes also another problem. When can a server node clear a session and release all resources associated with it? Since the http protocol itself is stateless a server can not safely decide when a http session can be cleared. The server relies on some kind of message from the client that says: “I don’t need the session anymore” Normally this is done via a logout request. But since the client server communication is done over a network that can be broken or the client unexpectly crashes this release the session message might never arrive at the server side. To handle this a server normally uses a session timeout. So when the http session has not been used for a specific duration, the server assumes that the client has gone away and releases the session. And here comes the conflict between client comfort and server resources. If the session timeout is too short a client might often loose it’s application state and must re-login. If the session timeout is too long the server’s memory gets full of orphan sessions.
Client side application state
In the last years a lot of client side framework based on javascript (e.g. angularjs) have been developed that allow an application to store it’s complete application state on the client side. If the complete application state is hold on the client side than we don’t need stateful application services anymore. Today the so called REST services are very popular stateless services. A REST service should be stateless in order to provide scalability. I said “should be statless” because I saw a lot of implementations that are not, because they still use a http session. To achieve statelessness the whole application state is hold on the client side. Therefore no http session exists and also not the http session problems described above (memory leaks, scalability problems). Nevertheless the statelessness brings other problems and we need ways to solve them.
Problems with stateless application services
If an application service or a REST service is stateless it means that a client can use any server node in a cluster that provides the application services for a request. This has a big advantage, because each server node can crash or being shutdown by system administrators without affecting the client. The client can simply use another server node and keep on operating. This approach is extremly simple as long as the client must not be securely identified or authenticated. So if an application service needs authentication it must be sure from who a request comes. A client can select an arbitrary server node for a request and this also means that a client must send the authentication information with each request. Since the authentication information is send by the client with every request the application must ensure that no attacker can send authentication information and therefore authenticate himself as someone other or in other words steal someone’s identity. Therefore the authentication information that a client sends with every requets must first be protected against:
These basic problems can be solved using the transport layer security (TLS ) or in other words using the HTTPS-protocol, because TLS prevents these attacks. Nevertheless there are more points of attack depending on the way the authentication information is send with every request even when https is used as we will se in the next sections.
Sending authentication information with every request
Since the main idea of a REST service is to use the capabilities of the http protocol, one approach could be using http basic authentication. The next section will only give a short overview about the http basic authentication since there are a lot of sources that describe it very well.
HTTP basic authentication
The HTTP basic authentication seamlessly fits into a REST service approach, because it is already specified by the http protocol and can therefore be handled by every http complient component, server, and so on. The authentication information will be send as a http header and will only be base64 encoded which is a reversible encoding. The http basic authentication header is constructed in the following way:
base64(<username>":"<password>)
base64("Aladdin:open sesame") = QWxhZGRpbjpvcGVuIHNlc2FtZQ==
The http header send to the server will then look like this:
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
There are security issues with this approach:
- The client must send the base64 encoded username/password with every request and therefore it must safe the password in plaintext somewhere in the client’s memory. If someonoe gets access to the clients memory one can read the password in plaintext.
- With every request the server decodes the base64 encoded username/password and must hold it in it’s memory for a short time until the user is authenticated.
But there are also problems with this approach beyond security issues:
- The server must validate the credentials on each request.
The Secure Cookie Protocol
The Secure-Cookie-Protocol is a way that a client can be authenticated on every request without repeating the authentication procedure and without sending the clients secret in plaintext over the network again and again. This is achieved by creating a server signed token that the client can use for further requests. The client can obtain a secure cookie in the following way:
- Client invokes an login service on the server by sending it the username and password.
- The server verifies the user’s identity. If the user can be authenticated the server continues with step 3.
- The server creates a token based on the user id, the date of issue and signs it with a key that only the server knows.
- The server sends a cookie back to the client that contains the user id and date of issue in plaintext as well as the signature (the Secure Cookie).
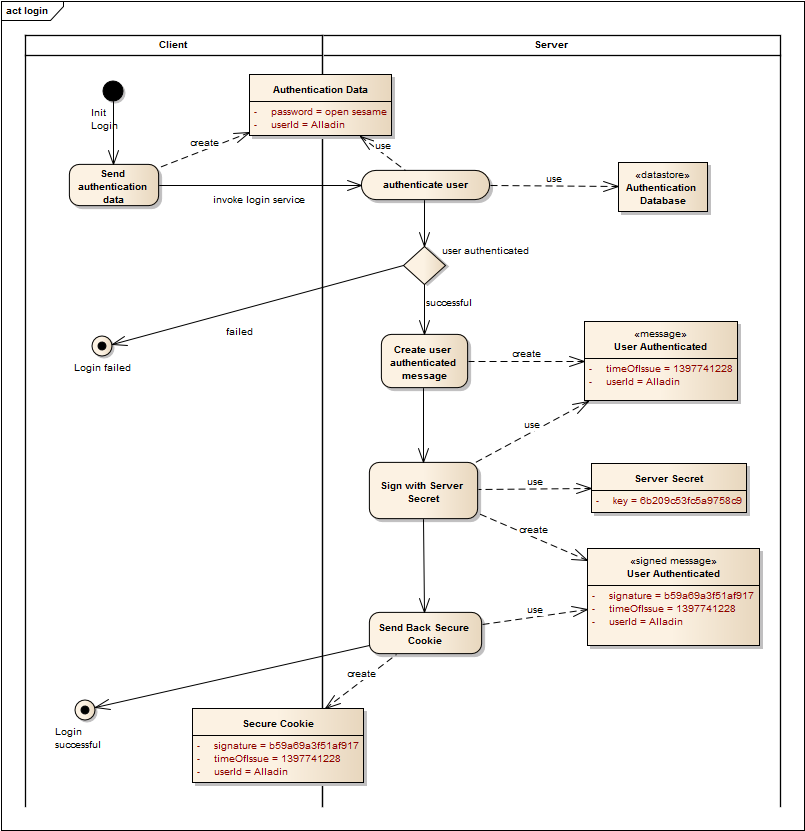 After a client has obtained a secure cookie it can send it with every request so that the server can verify the secure cookie. If the server can sucessfully verify the secure cookie it can suppose that the userId in the secure cookie is an authenticated user. The following diagram shows the verification process:
After a client has obtained a secure cookie it can send it with every request so that the server can verify the secure cookie. If the server can sucessfully verify the secure cookie it can suppose that the userId in the secure cookie is an authenticated user. The following diagram shows the verification process: 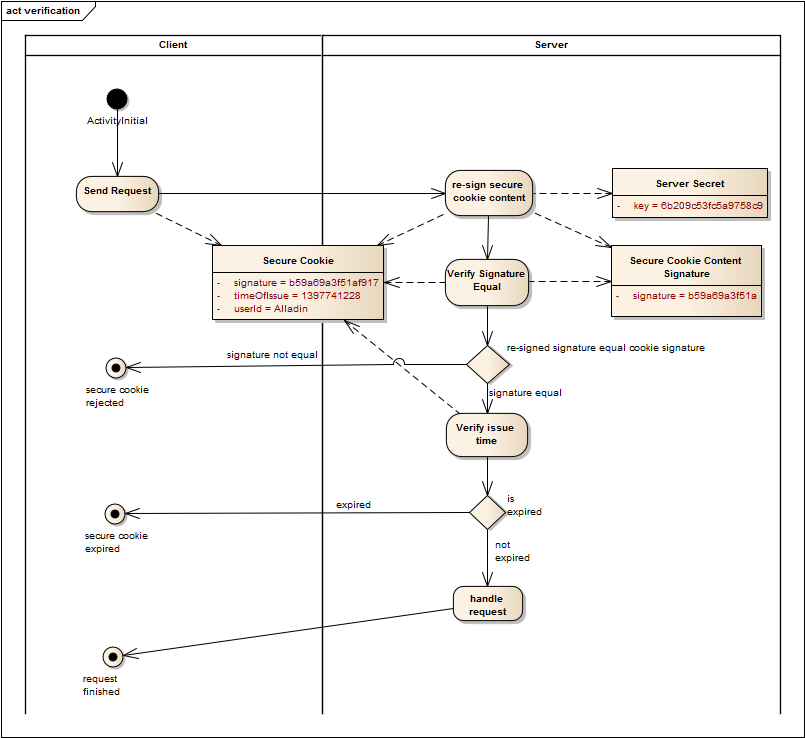
The secure-cookie-protocol implemented in Java
The following java code demonstrates how a secure cookie can be created and verified in Java. The example code is kept easy in order to understand the principles of how a secure cookie works. It is not meant to be used in production code, because there are more security issues to consider (e.g. the String signingSecret).
public class SecureCookieCA {
private long expriationTimeMs;
private String signingSecret;
public SecureCookieCA(long expriationTimeMs, String signingSecret) {
this.expriationTimeMs = expriationTimeMs;
this.signingSecret = signingSecret;
}
public SecureCookie issueSecureCookie(String userId) {
long timeOfIssue = System.currentTimeMillis();
String signature = sign(userId, timeOfIssue);
return new SecureCookie(userId, timeOfIssue, signature);
}
private String sign(String userId, long timeOfIssue) {
String toSign = createSignString(userId, timeOfIssue, signingSecret);
String salt = hash(toSign);
toSign = createSignString(userId, timeOfIssue, salt);
String signature = hash(toSign);
return signature;
}
private String createSignString(String userId, long time, String salt) {
return userId + Long.toString(time) + salt;
}
private String hash(String stringToHash) {
try {
String hashedString = null;
StringBuilder sb = new StringBuilder();
MessageDigest md = getMessageDigest();
md.update(stringToHash.getBytes());
byte[] bytes = md.digest();
for (int i = 0; i < bytes.length; i++) {
sb.append(Integer.toString((bytes[i] & 0xff) + 0x100, 16)
.substring(1));
}
hashedString = sb.toString();
return hashedString;
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException("Unable to issue secure cookie.", e);
}
}
protected MessageDigest getMessageDigest() throws NoSuchAlgorithmException, NoSuchAlgorithmException {
MessageDigest md = MessageDigest.getInstance("SHA-256");
return md;
}
public boolean isValid(SecureCookie secureCookie) {
String signatureToVerify = secureCookie.getSignature();
String userId = secureCookie.getUserId();
long timeOfIssue = secureCookie.getTimeOfIssue();
String signature = sign(userId, timeOfIssue);
boolean isSignatureValid = signatureToVerify.equals(signature);
Date expirationDate = getExpirationDate(timeOfIssue);
Date now = new Date();
boolean inTime = now.before(expirationDate);
return isSignatureValid && inTime;
}
protected Date getExpirationDate(long timeOfIssue) {
return new Date(timeOfIssue + expriationTimeMs);
}
}
class SecureCookie {
private String userId;
private String signature;
private long timeOfIssue;
public SecureCookie(String userId, long timeOfIssue, String signature) {
this.userId = userId;
this.timeOfIssue = timeOfIssue;
this.signature = signature;
}
public String getUserId() {
return userId;
}
public long getTimeOfIssue() {
return timeOfIssue;
}
public String getSignature() {
return signature;
}
}
Why hashing twice?
In the example code above you can see that the sign method first concatenates the userId, timeOfIssue and signingSecret (server secret) and hashs it and then uses the resulting hash as the salt of the “real” signing by hashing userId + timeOfIssue + salt.
Because the userId and timeOfIssue are plaintext and therefore readable by everybody the salt must be a very long string to prevent brute force attacks from being successful. A SHA-256 hash has 64 characters and is made up of the characters 0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f . So we have 16 different states for each character. Thus each character has 4 bit (2^4 = 16). All together have 64 * 4 bits = 256 bits. This means that a SHA-256 hash can represent 2^256 different values. That’s a lot: 1,16e+77. So if an SHA-256 hash gets SHA-256 hashed and an attacker wants to re-construct the first SHA-256 he must with a 50% chance of guessing at least try 5,79e+76 combinations of 0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f with a length of 64 characters.
For doing brute force attacks on SHA-256 hashes one might want to use a todays modern GPU, because they can do much more operations a second than CPUs can do. Nevertheless, even multiple GPUs (e.g. 25 GPUs) can “only” guess 348 billion hashes a second. Sounds very much but we remember that if we hash a SHA-256 as SHA-256 again the input string to guess itself has a length of a 64 characters. So with a 50% chance to guess the right input string one must try 1,16e+77 different input strings (in our case SHA-256 hashes) and this means even with 25 GPUs one will take about 1,06e+58 years. That’s the reason we hash the server secret first and use this SHA-256 as the signing salt.
Choosing the signing key
The signing key can be choosen in different ways and we want to take a look at them here. The only important requirement of how to provide a signing key is, that it will be the same key on every server in a collection of servers that the client should be able to choose.
- Static Key The key is defined as a constant in the soruce code. This approach has the advantage that it is simple, but if someone gets access to the sourcecode he knows the key and issue any secure cookie he wants. If the key should be changed the code must be recompiled and deployed.
- Configured Key A key is obtained by some kind of configuration, e.g. JNDI, properties file or a database. The advantage of this kind of key is that it can easily be changed. Even no restart of the application might be necessary.
- Calculated Key The key is calculated based on the environment of the application. The advantage is that it is hard to reconstruct. The disadvantage is that you must ensure that the same key is calculated on every server node. Otherwise a client can not transparently switch the server.
Http-only secure cookies
To make it more difficult for an attacker to get the secure cookie that is send to the client one can flag the secure cookie as http only. The cookie will then not be accessible by the client’s javascript code. Thus if an attacker injects javascript (XXS) he can still not get the secure cookie. A lot of browsers support the httpOnly flag today. An overview of the browsers that support http only cookies can be found on owasp.org. If you want to find out if your browser supports http only cookies you can try http://ha.ckers.org/httponly.cgi.
Secure Cookie vs. Token
A secure cookie is like a “normal” cookie handled by a client’s browser automatically and no specific client side implementation to handle it is necessary. Nevertheless a cookie is bound to a domain and therefore can not be used for cross-domain authentication out of the box. This is the point where the token or secure token comes in. When I described the secure cookie protocol in the previous sections you might have recognized that the main algorithm is not bound to the way the signed authentication information is transferred or stored on the client side. Thus one might not store it as a cookie but rather as a simple string (a token) on the client. The client can then send this token with every request to the server to authenticate itself. The advantage is that this token is not bound to a domain like a cookie, but the disadvantage is that it must be handled by the client code and there is no http only flag for it. So you have to make a decision based on your requirements which way you want to go.