
Some day you might want to remove files or directories from git permanently, because someone committed sensitive data or large binary files that should not reside in the repository to keep clone times short. In this blog I want to show you how to delete directories and files permanently from a git repository.
The first chapter is a short answer and is intended for those of you who only want to quickly remove files and don’t want to undestand it in-depth.
The section chapter dives into the depth of git and gives you links to other resources to understand how files are managed in git and thus can be removed.
The short answer
For those of you who are interessted in the fast way I will show you the git commands you need in order to remove directories and files or more general “paths” from a git repository. Therefore each step will only give a short explanation of what is done.
- Find the Snapshot which introduced some path
The first command prints out the commit hash in which the path was first introduced. <path> can be a directory or a file path relative to the working directory root. In the example the first commit’s hash is 970c2521424856a774ed8c83a1aab99a79e53464 or in the short form 970c252.git log --reverse -- <path> | head -n 1
The command’s output will be something like this
commit 970c2521424856a774ed8c83a1aab99a79e53464
- Find the Snapshot in which the path was removed
The next command prints out the commit hash in which the path was removed. <path> can be a directory or a file path relative to the working directory root. In the example the last commit’s hash is 2e746b23f09a006a3381292dc264ada4ba5e9ff8.git log -1 -- <path> | head -n 1
The command’s output will be something like this
commit 2e746b23f09a006a3381292dc264ada4ba5e9ff8
- Remove all paths from the repository and rewrite the commits
The next command removes the path from the repository of all commit from 8727af97714eded773da4b3b1c38ba4bfd73b0a6 to 2e746b23f09a006a3381292dc264ada4ba5e9ff8 . The option –index-filter is used to improve performance since the working directory is not checked out for each commit. Instead the index area is used.git filter-branch --index-filter 'git rm -rf --cached --ignore-unmatch <path>' --prune-empty --tag-name-filter cat -- <from_commit_id>^1..<to_commit_id> --all
Alternatively one can filter all commits by just ommiting the commit id range.
git filter-branch --index-filter 'git rm -rf --cached --ignore-unmatch <path>' --prune-empty --tag-name-filter cat -- --all
If git filter-branch works you should see something like this in the output
Rewrite 7ccdce1a692fe3a5b12da0eff15127a0abf5a849 (171/18232)rm '<path>/**' rm '<path>/**' rm '<path>/**' rm '<path>/**' rm '<path>/**' rm '<path>/**' Rewrite af626803fa2fe3a5b12da0eff1296b0abffa53 (172/18232)rm '<path>' rm '<path>/**' rm '<path>/**' rm '<path>/**' rm '<path>/**' rm '<path>/**'
- Remove the backup refs
The git filter-branch command will create backup refs in .git/refs/original. These refs must be deleted in order to remove references to these objects.git for-each-ref --format="%(refname)" refs/original/ | while read ref; do git update-ref -d $ref; done
- Remove refs from the reflog
Also the reflog might contain references to the path that we want to delete. Thus we need to clear the reflog in order to remove references to the objects we want to delete.git reflog expire --expire=now --all
- Run garbage collection to wipe out unreferenced objects
Git’s garbace collector will remove all objects that are not references by commits anymore.git gc --prune=now
- Verify that the path was completely removed
If the next command does not produce any output than the <path> does not exist anymore in the repository.git rev-list --objects --all -- <path>
- Push changes to the remote repository
Remember that the path removal process has rewritten the history and therefore a forced push is necessary. But this also means that developers who have cloned the repository before will get in big trouble if they try to pull the next time. So you must inform them about the changes and that they have to clone the repository again after the path removal.Togglegit push origin *:* --force
Using a single command line
If you don’t want to execute all commands step by step you can also set the GIT_DELETE_PATH environment variable and use this single command line
git filter-branch \
--index-filter "git rm -rf --cached --ignore-unmatch $GIT_DELETE_PATH" \
--tag-name-filter "cat" \
-- \
`git log --reverse -- $GIT_DELETE_PATH | head -n 1 | awk '{ print $2 "^1" }'`..`git log -1 -- $GIT_DELETE_PATH | head -n 1 | awk '{ print $2 }'` \
--all \
&& \
git for-each-ref --format="%(refname)" refs/original/ | xargs -n 1 git update-ref -d \
&& \
git reflog expire --expire=now --all \
&& \
git gc --prune=now
Using a bash script
If you have to do deletion jobs often you should consider to use a bash script like this
#!/bin/bash
GIT_DELETE_PATH=$*
git filter-branch \
--index-filter "git rm -rf --cached --ignore-unmatch $GIT_DELETE_PATH" \
--tag-name-filter "cat" \
-- \
`git log --reverse -- $GIT_DELETE_PATH | head -n 1 | awk '{ print $2 "^1" }'`..`git log -1 -- $GIT_DELETE_PATH | head -n 1 | awk '{ print $2 }'` \
--all \
&& \
git for-each-ref --format="%(refname)" refs/original/ | xargs -n 1 git update-ref -d \
&& \
git reflog expire --expire=now --all \
&& \
git gc --prune=now
If you save the bash script in a file called git_delete_paths.sh you can use the script like this
$ git_delete_paths.sh lib someProject/lib
Performance considerations
Rewriting the history of a large repository might take a long time. Even if the faster –index-filter options is used. While I tried a lot of performance improvements I want to list my experiences here and hope it will help you.
git filter-branch on windows vs. linux
I could figured out that a git filter-branch is much slower on windows than on linux systems. So if you have the choice you should do it on a linux system. Also a virtual linux machine was much faster than doing the same in the windows git bash.
Using a ramfs to do a git filter-branch on a large repository
Since git filter-branch is used to rewrite the history it does a lot of IO operations. Therefore you can dramatically increase the throughput by using a ramfs.
On my ubuntu system I created a ramfs using:
$ sudo mkdir /mnt/ramfs $ sudo mount -t tmpfs -o size=4G none /mnt/ramfs
In my case I created a ramfs or tmpfs with a size of 4 GB. Choose an appropriated size for your case. The tmpfs must be large enough to hold your git repository clone. Also make sure that you do not exceed your systems free memory.
After that clone your repository (or just copy it) into the /mnt/ramfs directory and do the filter branch there.
Git file management details
This section takes a closer look at the way that git manages files and the removal process. You should read this section if you want to know what the git commands shown above really do.
How files are managed in git
In order to understand how files and directories can be removed one must understand how files are managed in git.
All data in git is stored in objects. Each object has a specific type that specifies which kind of data it contains and there are different types of objects.
The main types for storing files are:
- tree
Tree objects represent the directories in a filesystem. They have references to other tree objects or blob objects. - blob
Blob objects represnt the files in a filesystem. They hold the binary data that the file contains.
The following figure shows a conceptual model of how directories and files are represented by git objects.
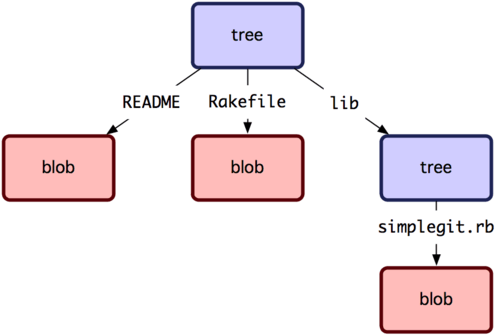
Conceptual model of git file management
Git objects are stored in the repository under the objects directory. For more details take a look at Git-Internals-Git-Objects.
So if we can rewrite the pointers of tree objects to blob objects we can remove blob objects from the repository and if we rewrite pointers to trees we rewrite directory structures.
But before we start we also have to know how tree objects are mapped to commits since we also have to modify the commits.
I said before that all data in git is stored in objects. Thus each commit itself is an object of type commit and a commit points to a tree object. So if we rewrite the commit’s tree pointer we rewrite the complete tree that is connected to that commit.
The following figure shows how commit objects reference tree objects and blob objects.
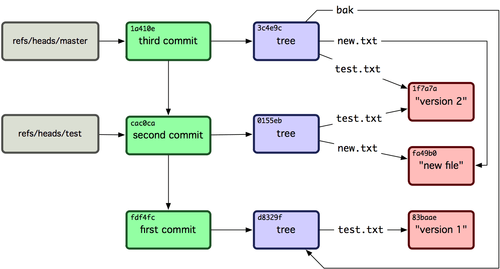
Git References
So now it gets more and more clear what we have to do if we want to remove a file or directory from all commits in git. We must rewrite the tree objects that a commit references or even remove tree objects completely fr0m a commit.
The abstract algorithm can be defined like this:
- Find the commit that first introduced some path (e.g. lib/commons-io.jar — tree -> blob)
- Loop through all commits from the first until the last commit that contains some path
- For each commit reqrite the tree objects and pointers
- Remove all objects that are not referenced anymore by commits.
Git file and directory removal explained
This section will review the commands that the first chapter shows and take a deeper look at their arguments in order to understand how the removal process works.
1. Find the Snapshot which introduced some path
$ git log --reverse -- <path> | head -n 1 commit 8727af97714eded773da4b3b1c38ba4bfd73b0a6
The git log command is used to query commits. You can specify a path at the end of the command that is separated by —. If you do that the git log only prints out commits which affect that path in some way. With the –reverse argument we define that we want the commits in reverse order. Thus the first commit ever made that affects the given path is the first one that git log prints out. Since we are only interressted in that commit we use head -n1 1 to only print the first line of the git log command, because this line contains the snapshot’s hash.
2. Find the Snapshot in which the path was removed
$ git log -1 -- <path> | head -n 1 commit 2e746b23f09a006a3381292dc264ada4ba5e9ff8
In this example we use the -1 to tell git that we only want to get 1 commit and this commit will be the last commit that affects the path. Since we are only interressted in that commit we use head -n1 1 to only print the first line of the git log command, because this line contains the snapshot’s hash.
3. Remove all paths from the repository and rewrite the commits
$ git filter-branch --index-filter 'git rm -rf --cached --ignore-unmatch <path>' --prune-empty --tag-name-filter cat -- 8727af97714eded773da4b3b1c38ba4bfd73b0a6^1..2e746b23f09a006a3381292dc264ada4ba5e9ff8 --all
The git filter-branch command is used to loop over a selection of commits and execute some other command on each commit. In our case the filter-branch command uses the –index-filter argument which increases the performance, because –index-filter means that each commit will not be checked out. Instead only the index or staging are will be reconstituted. But this come at a price. The trade-off is that you can only use git commands in the command argument. If you want to use every command that is available at the command-line you can use –tree-filter instead. But a –tree-filter does a complete checkout of each commit and therefore is not as performant as the –index-filter.
Since we use the –index-filter we must use git’s rm command to delete files and folders. The –index-filter only works on the index and therefore we must add –cached to the rm command. Finally we also add –ignore-unmatch so that the command returns successfully even if no files are removed.
To allow rewrite of tags that might be affected by the path removal we add –tag-name-filter cat which updates the tags.
The –prune-empty argument tells filter-branch to prune empty commits. So if the git rm -rf will remove all files from a commit and therefore ending up in an empty commit the whole commit will be removed. This might be what you want if someone committed all the files in one commit. If you don’t want this behavior for some reason just remove the –prune-empty argument.
One of the most important parts of the command is the part where you define the history range to filter. In the example above it is 8727af97714eded773da4b3b1c38ba4bfd73b0a6^1..2e746b23f09a006a3381292dc264ada4ba5e9ff8. The very important part is the ^1 at the end of the first snapshot. The from-part of the range is interpreted as exclusive. So the filter-branch will normally start at the next snapshot. Therefore we use ^1 which is a shortcut for the direct parent of the current snapshot. If you forget the ^1 you will not be able to delete the fieles, because snapshot 8727af97714eded773da4b3b1c38ba4bfd73b0a6 will not be processed and therefore hold references to the objects and git gc can’t clean the references than.
4. Remove the backup refs
$ git for-each-ref --format="%(refname)" refs/original/ | while read ref; do git update-ref -d $ref; done
The git for-each-ref command loops through git references and you can output the references in a format that you want. Since we executed git filter-branch and removed filtes git makes a backup of the original refs in refs/original. So these refs still reference the files we want to remove. Thus we need to remove the backup references in order to make the files eligible for garbage collection. So we have to read every ref and delete it using git update-ref -d $ref.
5. Remove refs from the reflog
$ git reflog expire --expire=now --all.
The git reflog a mechanism that records reference updates. It is very helpful if you accidentally remove some reference. In our case it is not helpful since we want to remove files permanently and therefore must remove all references to them in order to make the files eligible for garbage collection. Therefore we clear the reflog completely with the arguments expire –expire=now –all.
6. Run garbage collection to wipe out unreferenced objects
$ git gc --prune=now
After we removed all references to the files we want to delete we execute gc –prune=now which runs git’s garbage collector. The garbage collector identifies all objects (tree, blob, …) that are not references by a commit anymore and deletes them. Normally git gc has a grace period of 2 weeks. We don’t want to wait 2 weeks until the objects get deleted so we tell git gc that it should prune the objects now.
LIKE 🙂
Pingback: Link Intersystems – GitDirStat – a git maintenance gui
Pingback: git filter-branch remove folder failed - DexPage
Step 3 shows those removal lines and ends with WARNING: Ref ‘refs/heads/master’ is unchanged. All further steps “work” as until Step 7 shows the folders. I copied and pasted all of the commands and I’m seeing the correct output for steps 1 and 2. I’m using the ^1 for step 3 using the correct commits. Not sure what’s going on here. Ultimately, the entire process is not working for me. Where should I look?